
oct.
2012
Structures de données : les Arbres de Fenwick
Si je vous demande de me citer des structures de données, vous répondrez sans doute : les tableaux, les listes chaînées, les Maps, les Sets, voire les arbres binaires... Ces structures sont simples et d'un usage courant, et suffisent pour la plupart de nos besoins.
Dans certain cas toutefois, les structures basiques atteignent leurs limites, et il est nécessaire de recourir à des structures spécialisées. Aujourd'hui, je vous présente les Arbres de Fenwick.
Use-case
Un Arbre de Fenwick est particulièrement adapté pour calculer une somme partielle entre deux bornes.
Prenons l'exemple d'une application effectuant des transactions financières. La banque aimerait pouvoir déterminer en temps réel le nombre de transactions portant sur des montants compris entre deux bornes variables, par exemple entre 12000€ et 15000€.
Une solution simple consisterait à stocker ces informations dans un tableau, associant à chaque montant un compteur de transactions :
1 € : 91 transactions
2 € : 11 transactions
3 € : 127 transactions
...
10000 € : 278 transactions
10001 € : 25 transactions
10002 € : 103 transactions
...
14998 € : 422 transactions
14999 € : 49 transactions
15000 € : 8 transactions
Pour calculer le nombre de transactions portant sur des montants compris entre 12000 € et 15000 €, il suffit de parcourir le tableau entre les indexes 12000 et 15000 et de faire manuellement la somme des valeurs associées.
Cette technique, qui a le mérite de la simplicité, fonctionne bien pour des petits intervalles (quelques milliers) ; mais au-delà, les performances sont épouvantables, car le parcours linéaire du tableau induit une complexité en O(n), c'est-à-dire directement proportionnelle au nombre d'éléments parcourus.
A problème spécifique, solution spécifique : les Arbres de Fenwick à la rescousse !
Principes
Vu de l'extérieur, un Arbre de Fenwick ressemble beaucoup à un tableau. Il permet de stocker des valeurs selon des indexes, et pour un index donné il est possible de lire ou de modifier (incrémenter/décrémenter) la valeur associée.
L'implémentation interne est en revanche totalement différente.
Dans un tableau, un index stocke uniquement la valeur dont il est responsable ; dans un Arbre de Fenwick, un index stocke une somme partielle, c'est-à-dire la somme des valeurs des sous-indexes dont il est responsable, eux-mêmes représentant la somme d'autres sous-indexes, etc. On est donc en présence d'une hiérarchie complexe d'indexes, et non plus d'une structure plate.
Comment savoir de quels indexes un index particulier est responsable ?
C'est très simple : il suffit de savoir compter en binaire. Par exemple, pour les indexes de 1 à 15 :
idx binaire 15 00001111 14 00001110 13 00001101 12 00001100 11 00001011 10 00001010 9 00001001 8 00001000 7 00000111 6 00000110 5 00000101 4 00000100 3 00000011 2 00000010 1 00000001 0 00000000
Pour chaque index, on part de la droite de sa représentation binaire, et on remonte les bits jusqu'à tomber sur un 1. Cela crée une barrière virtuelle entre le premier bit à droite et ce 1. A partir du 1, on tente de descendre jusqu'au bas du tableau, vers l'index 0. Lorsqu'on est bloqué par une barrière préexistante ou qu'on est arrivé à l'index 0, il suffit de regarder quels indexes on a croisé sur le chemin de la descente : on en sera responsable.
Allez, un petit schéma vaut mieux qu'un long discours, alors hop :

Selon ce principe :
idx responsable de 1 1 (atteint l'index 0) 2 2, 1 (atteint l'index 0) 3 3 (bloqué par l'index 2) 4 4, 3, 2, 1 (atteint l'index 0) 5 5 (bloqué par l'index 4) 6 6, 5 (atteint l'index 0) 7 7 (bloqué par l'index 6) 8 8, 7, 6, 5, 4, 3, 2, 1 (atteint l'index 0) 9 9 (bloqué par l'index 8) 10 10, 9 (bloqué par l'index 8) 11 11 (bloqué par l'index 10) 12 12, 11, 10, 9 (bloqué par l'index 8) 13 13 (bloqué par l'index 12) 14 14, 13 (bloqué par l'index 12) 15 15 (bloqué par l'index 14)
Et vous avez sans doute deviné que l'index 16 couvrirait l'intervalle [0..16]. Vous voyez, c'est facile !
La règle est très mécanique et ne fait appel qu'aux propriétés des puissances de deux, qui peuvent être calculées de manière très efficace.
Performances
En écriture
Puisque la valeur à un index donné intervient dans plusieurs sous-totaux, le coût de mise à jour de la structure est plus important qu'avec un tableau : il faut potentiellement changer N entrées.
Par exemple, si on incrémente de 1 la valeur de l'index 2, il faut également mettre à jour les index 4 et 8.
En lecture
En revanche, lorsqu'il s'agit de calculer des sommes, l'Arbre de Fenwick est extrêmement efficace.
Tout d'abord, remarquons que pour calculer la somme des index entre 0 et N, il suffit d'additionner les valeurs des quelques index permettant de couvrir l'intervalle [0..N].
Par exemple, la somme des valeurs des index de 0 à 7 est obtenue en additionnant les valeurs des index 7, 6 (qui couvre 6 et 5), et 4 (qui couvre de 0 à 4).
Comme les index couvrent de plus en plus de sous-index (ex: l'index 16 couvre [0..16]), la complexité est en O(log n), c'est-à-dire qu'il ne coûte pas beaucoup plus cher de récupérer la somme des index [0..100000] que [0..100].
Maintenant, comment récupérer la somme des valeurs entre deux index A et B ? C'est simple, il suffit de faire la différence entre les sommes des plages [0..B] et [0..A].
Par exemple, pour calculer la somme des valeurs entre 1000 et 1000000 : [0..1000000] - [0..1000], ce qui est calculable en quelques opérations seulement.
Pour vous donner une idée de la différence de performance entre un Arbre de Fenwick et un tableau, j'ai mesuré le temps nécessaire au calcul de la somme entre [0..1000], [0..2000], etc. jusqu'à [0..500000].
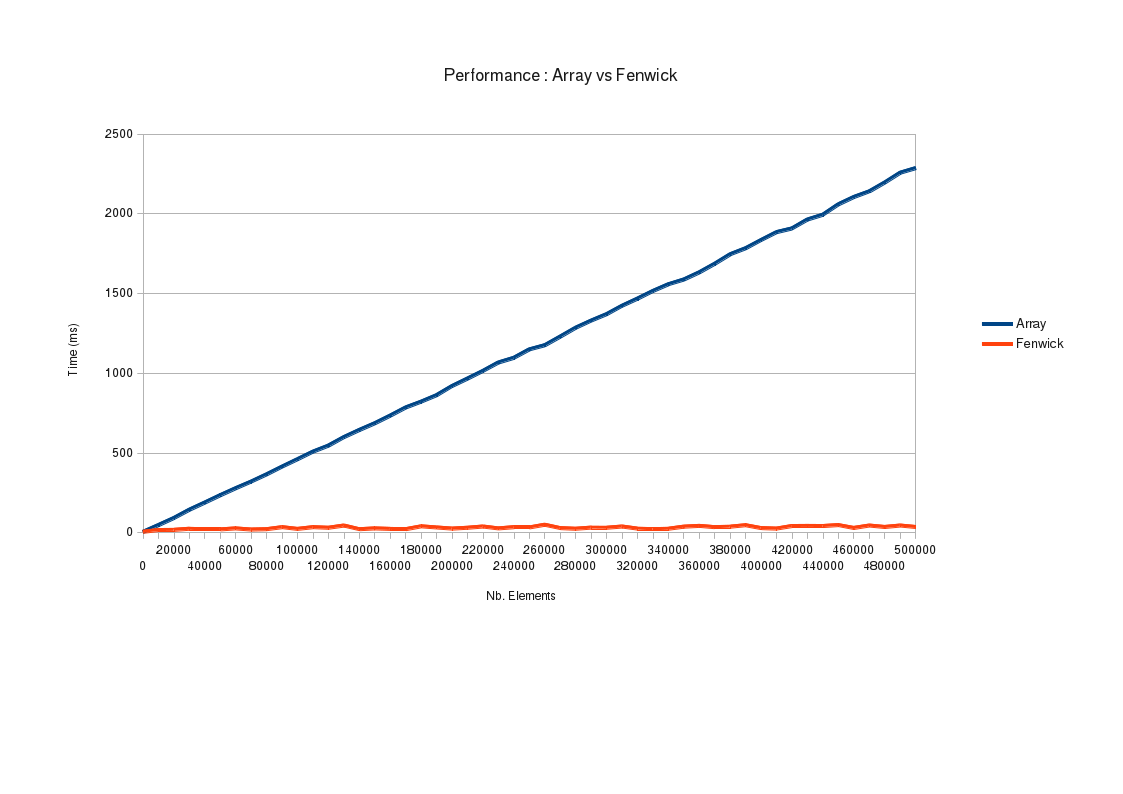
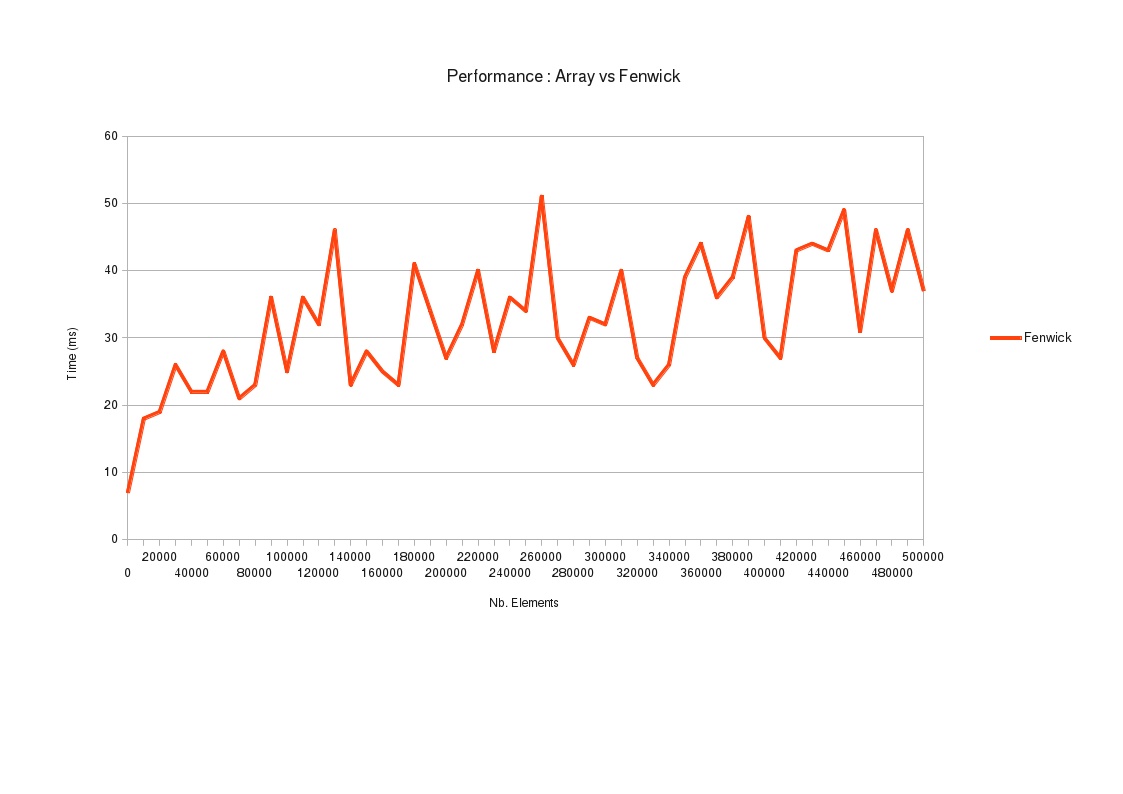
Si on zoome sur la courbe de Fenwick, on constate une tendance générale en log(n). Son irrégularité vient du fait que la complexité de calcul de [0..N] peut être très différente de celle de [0..N+1], selon la façon dont les zones de responsabilité des index se recouvrent.
Evidemment, vous pourrez m'objecter que ce benchmark ne mesure que le temps de calcul sur un intervalle de type [0..N], et pas entre deux bornes A et B arbitraires. Le temps serait environ doublé puisqu'il faudrait calculer [0..A] et [0..B], et il faudrait également faire une soustraction, mais l'ordre de grandeur ne serait guère différent.
Implémentation
Vous trouverez en pièce jointe du billet une implémentation en Java.
J'ai apporté une petite amélioration au principe, afin de gérer des plages d'index arbitraires, du moment que la différence entre l'index maximal et l'index minimal ne dépasse pas Integer.MAX_VALUE (puisque le tableau sous-jacent est indexé par un int.
Cela permet par exemple de gérer des indexes de 10000 à 20000 et non pas de 0 à 20000.
Un peu de code pour vous montrer la classe en action :
// Instanciation, indexes de 1 à 16 (inclus) Fenwick fenwick = new Fenwick(1, 16); System.out.println(Arrays.toString(fenwick.values)); // [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] // A l'index 1, j'ajoute la valeur 42. // Cette valeur est répercutée sur les index 2, 4, 8 et 16 qui couvrent également l'index 1 fenwick.add(1, 42); System.out.println(Arrays.toString(fenwick.values)); // [0, 42, 42, 0, 42, 0, 0, 0, 42, 0, 0, 0, 0, 0, 0, 0, 42] // A l'index 5, j'ajoute 1 // Cette valeur est répercutée sur les index 6, 8 et 16 qui couvrent également l'index 5 fenwick.add(5, 1); System.out.println(Arrays.toString(fenwick.values)); // [0, 42, 42, 0, 42, 1, 1, 0, 43, 0, 0, 0, 0, 0, 0, 0, 43] // Vérifions la valeur à l'index 1 (normalement 42) long valueAt1 = fenwick.valueAt(1); System.out.println(valueAt1); // 42 // Et à l'index 8 (normalement 0, on n'y a rien inséré) long valueAt8 = fenwick.valueAt(8); System.out.println(valueAt8); // 0 // Calculons la somme des valeurs entre les index 0 et 10 long upto10 = fenwick.sumUpto(10); System.out.println(upto10); // 43 (42 à l'index 1, + 1 à l'index 5) // Et entre deux index arbitraires, par exemple 4 et 12 long sumBetween4And12 = fenwick.sumBetween(4, 12); System.out.println(sumBetween4And12); // 1 (1 à l'index 5)
Conclusion
Utiliser les bonnes structures de données est absolument vital pour les performances de vos applications. Au-delà de celles fournies par le JDK, il en existe de nombreuses autres qu'il est intéressant de connaître.
Chacune possède un domaine d'application spécifique, et des avantages et inconvénients spécifiques : performances en lecture et écriture, occupation mémoire, puissance de calcul requise... Mais elles feront des miracles si vous tombez pile sur le bon use-case.
Révisez vos structures de données et vos design patterns, vos applications vous remercieront !
PS : vous trouverez en pièce jointe une implémentation de l'Arbre de Fenwick en Java, ainsi que le benchmark présenté dans l'article.


